
Effectiveness of AI Coding Techniques: Input & Context
A series where I analysis the effectiveness of various AI coding techniques. First post focuses on input and context related techniques.

There are so many AI coding tips and techniques, but which are the ones that are actually effective?
In this series of posts, I will analyze some AI coding techniques in terms of maturity and effectiveness:
Has the technique been mature and stable, or is it an emerging technique that is still evolving?
Is the technique effective in achieving better coding performance, or reducing cost?
For the first post, we will focus on techniques related to input and context management.
1. Prompt Engineering
Mature. Effective.
Prompt engineering is as old as the launch of ChatGPT. And it is still one of the most valuable techniques for AI coding. Being able to articulate task requirements clearly helps models become more effective.
Top AI companies have dedicated guides for prompt engineering:
There are also community-driven prompt engineering guides, and specialized prompt optimizer tools like DSPy. Some products like Devin have built-in tool to improve the prompt.
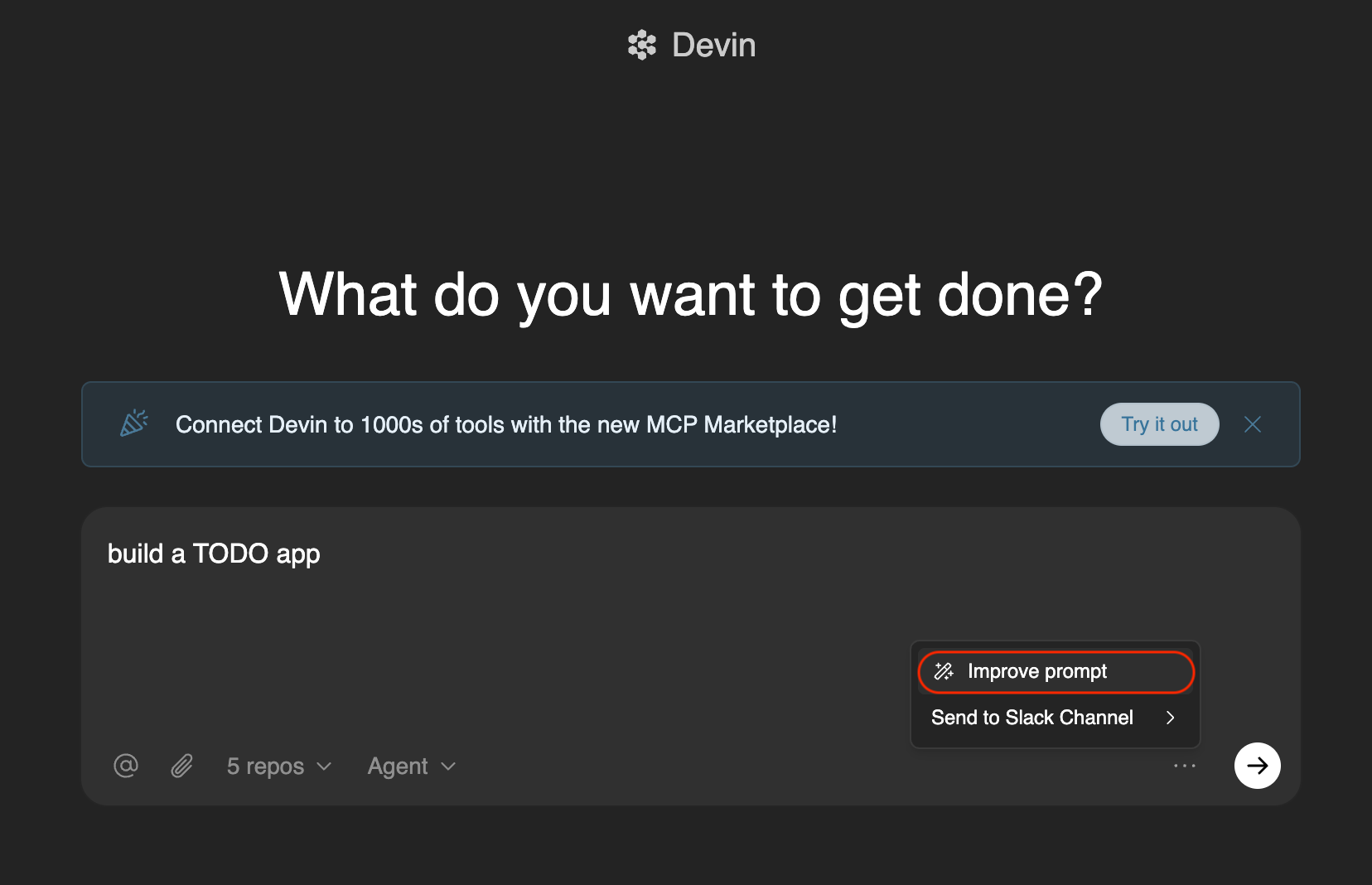
I have written some prompting tips in 2024 for using ChatGPT for coding, which are still relevant today.
All these effort goes to show that prompt engineering remains a key technique for effective coding using AI.
2. Retrieval-Augmented Generation (RAG)
Mature. Effective.
RAG is also an old technique, that was widely used for building custom chatbots linked to an internal knowledge base.
Cursor popularized the technique for coding, as it uses RAG to build an embedding model of the codebase (codebase indexing). This was effective for codebases that are medium-sized and allow models to gather context quickly.
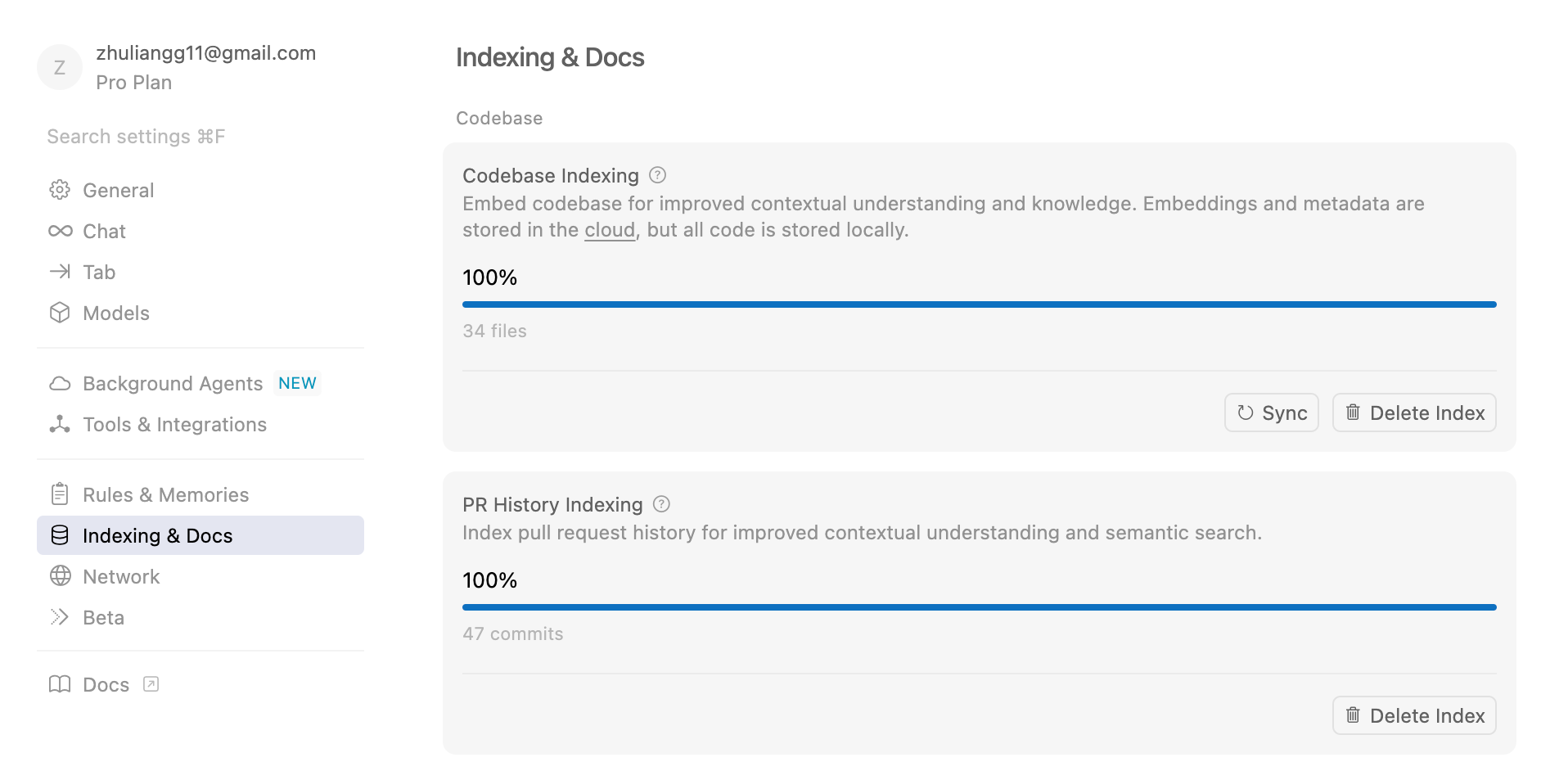
However, due to the limits on models' context window size, RAG is not particularly effective on very large codebases, such as mono-repos with hundreds of microservices inside.
RAG also requires vectorizing the codebase, storing and retrieving these vectors somewhere, performing computations to determine the relevant chunks, all of which add complexity to the workflow.
3. Context Engineering
Emerging. Effective.
There are new emerging techniques that provide alternative ways to gather context without relying on embeddings and vectors.
These are called context engineering, which involves using tools to gather context from the codebase. It can be codemap or command-line (CLI) tools like grep and git. The use of tools to search around the codebase mirrors how engineers would go about finding relevant code in real world.
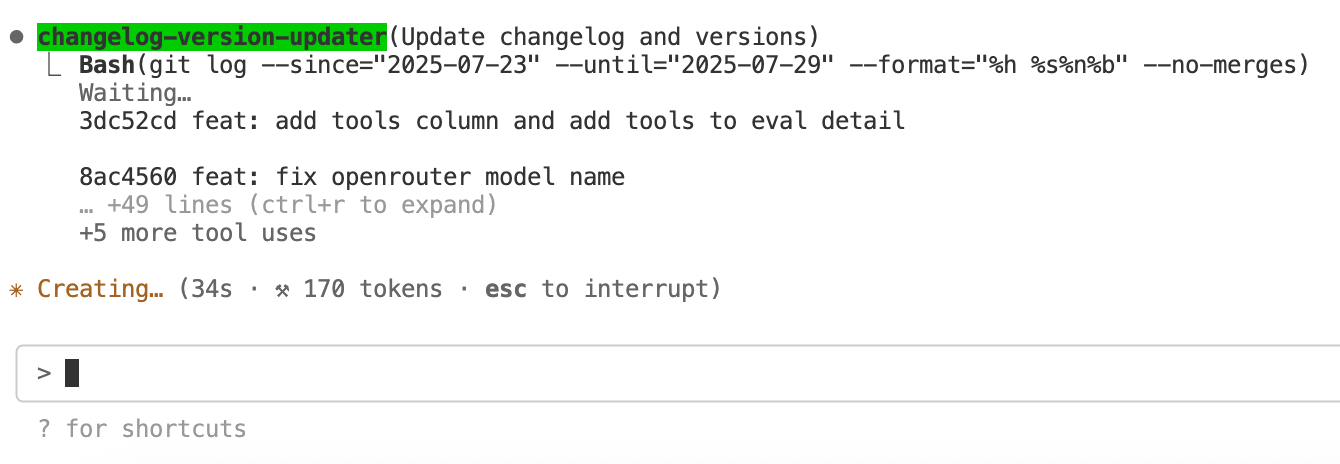
I consider context engineering an alternative form of RAG, as it also involves context retrieval and feeding it into the model for generation.
Context Engineering is popularized by tools like RepoPrompt and more notably Claude Code. The wide adoption of Claude Code proves its effectiveness as an emerging technique that is still evolving.
4. Rules / AGENT.md
Emerging. Limited Effectiveness.
Rules are popularized by AI coding tools like Cursor and Cline. They are typically written by human developers, while Claude Code can generate rules (CLAUDE.md) automatically via /init command.
Different tools have different syntax and naming conventions for the rules, but they all basically do the same thing: Provide general instructions and guide AI models.
When used well, they can help reduce the need to repeat general instructions or repo-specific guidelines to the model.
However, there are a few issues with current implementation of rules:
Sometimes models can ignore rules and do its own things. It is important to treat them as guidelines instead of rules that models will follow religiously.
A large rule / CLAUDE.md file can fill up the context window quickly, resulting in reduce quality of output as models perform worse with longer context.
The rules can become outdated as the codebase undergoes structural changes or refactoring. A tip to mitigate this is to run the
/initcommand regularly in Claude Code to update the rules.
There are also efforts to standardize the rules across tools as AGENT.md to reduce cluttering of the various rules in the code repos, which can help the rules to become more universal and effective.
5. Knowledge / Memory
Emerging. Limited Effectiveness.
Knowledge is a technique first seen in Devin. New knowledge is automatically proposed when the agent is working on a task and receives feedback from the user.
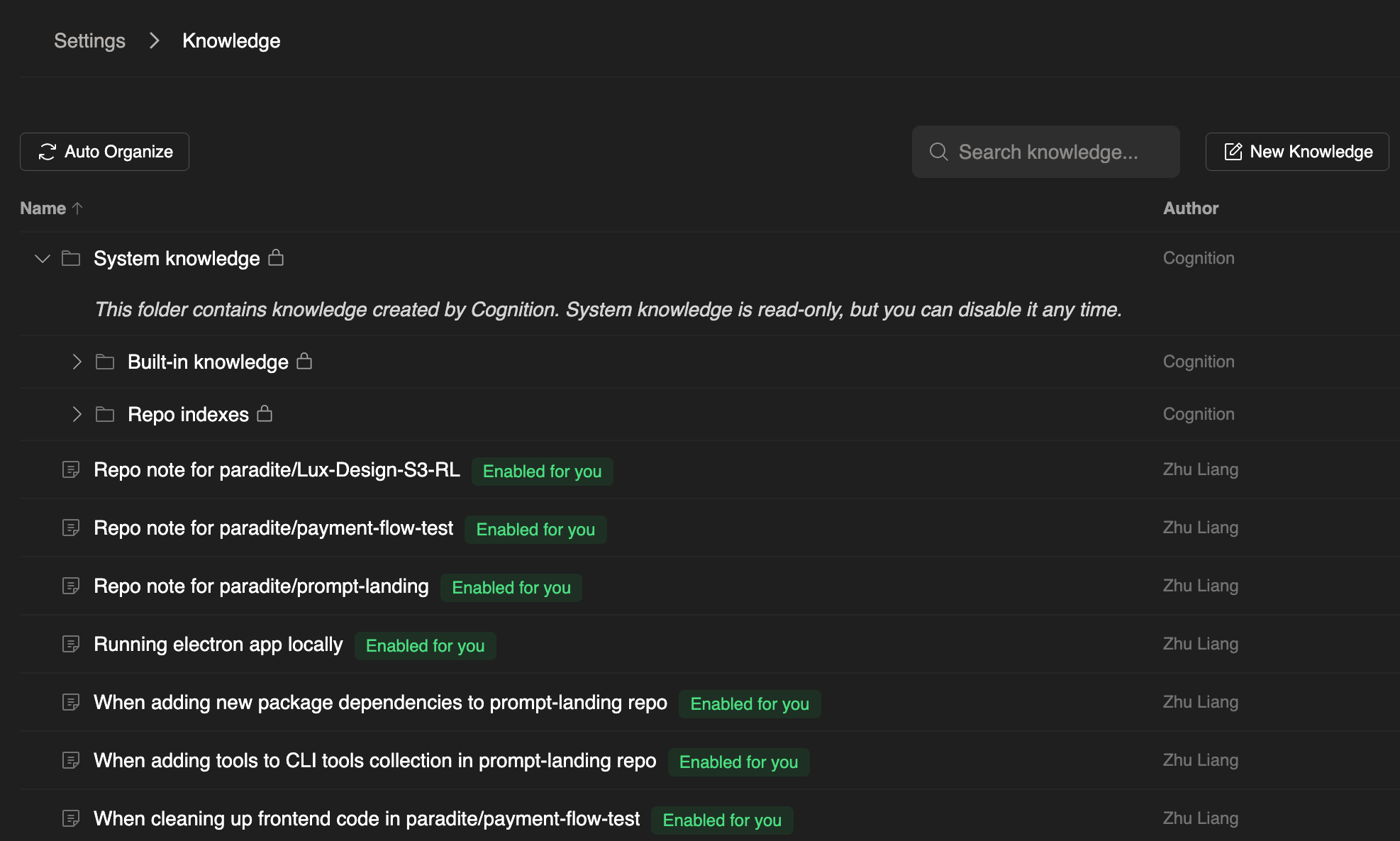
In Claude Code, this feature is called memory and shares the same CLAUDE.md file with rules. Unlike Devin, memory in Claude Code is not automatically proposed by the agent. Instead, the user need to use # commands to add new memory or edit the CLAUDE.md file directly.
Cursor also recently added the memory feature, which is automatically proposed, similar to Devin.
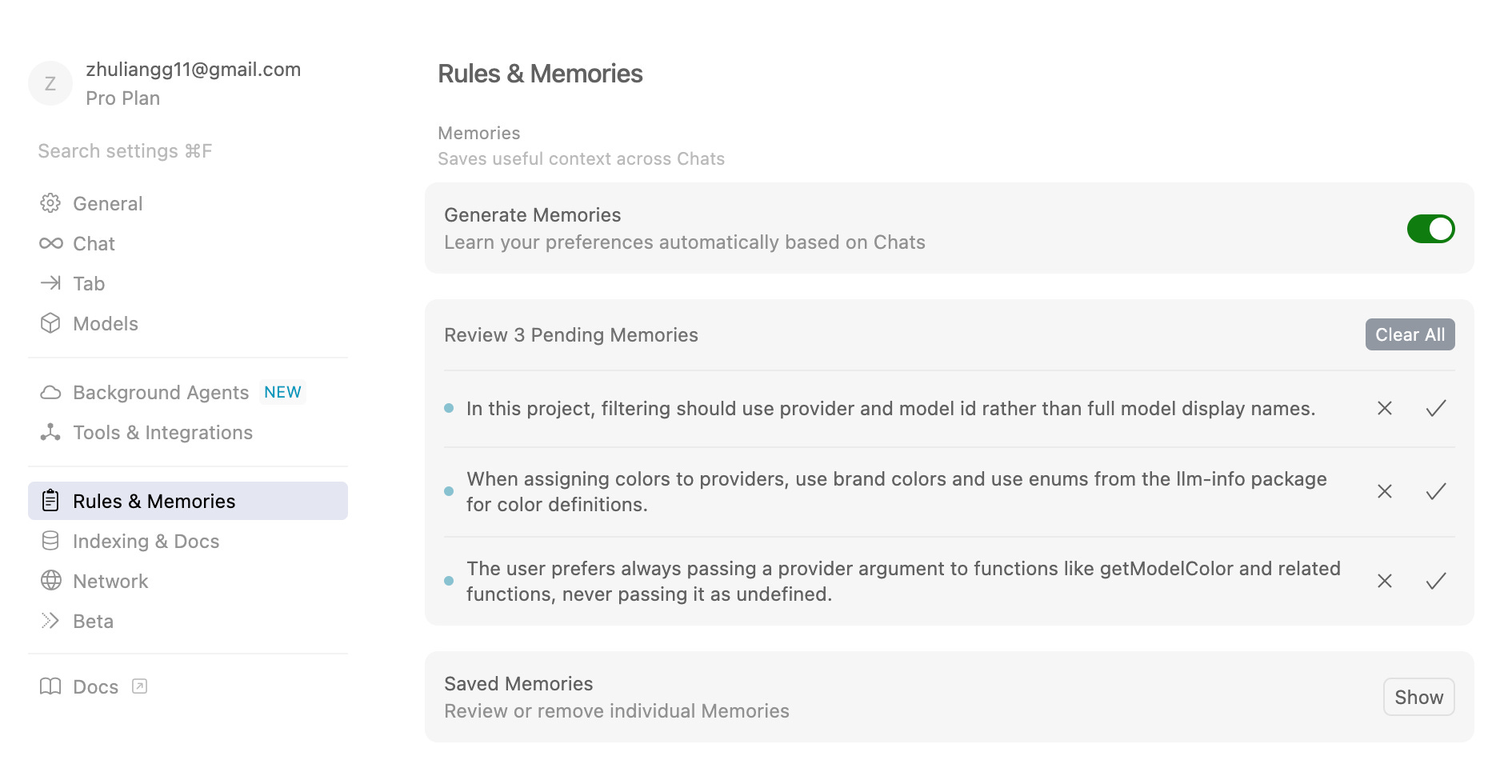
Based on my experience with Devin (January 2025) and Claude Code (July 2025), the knowledge / memory technique has limited effectiveness:
The automatically proposed knowledge is a mixture of useful general guideline and one-off comments that are likely not useful for other tasks. Very low precision and signal-to-noise ratio to be useful.
The manual proposal of memory in Claude is not very intuitive in terms of user experience, and the generated memory don't fully capture the user's intent based on the context.
As of now, it more effective to write rules manually instead of using the knowledge / memory feature.
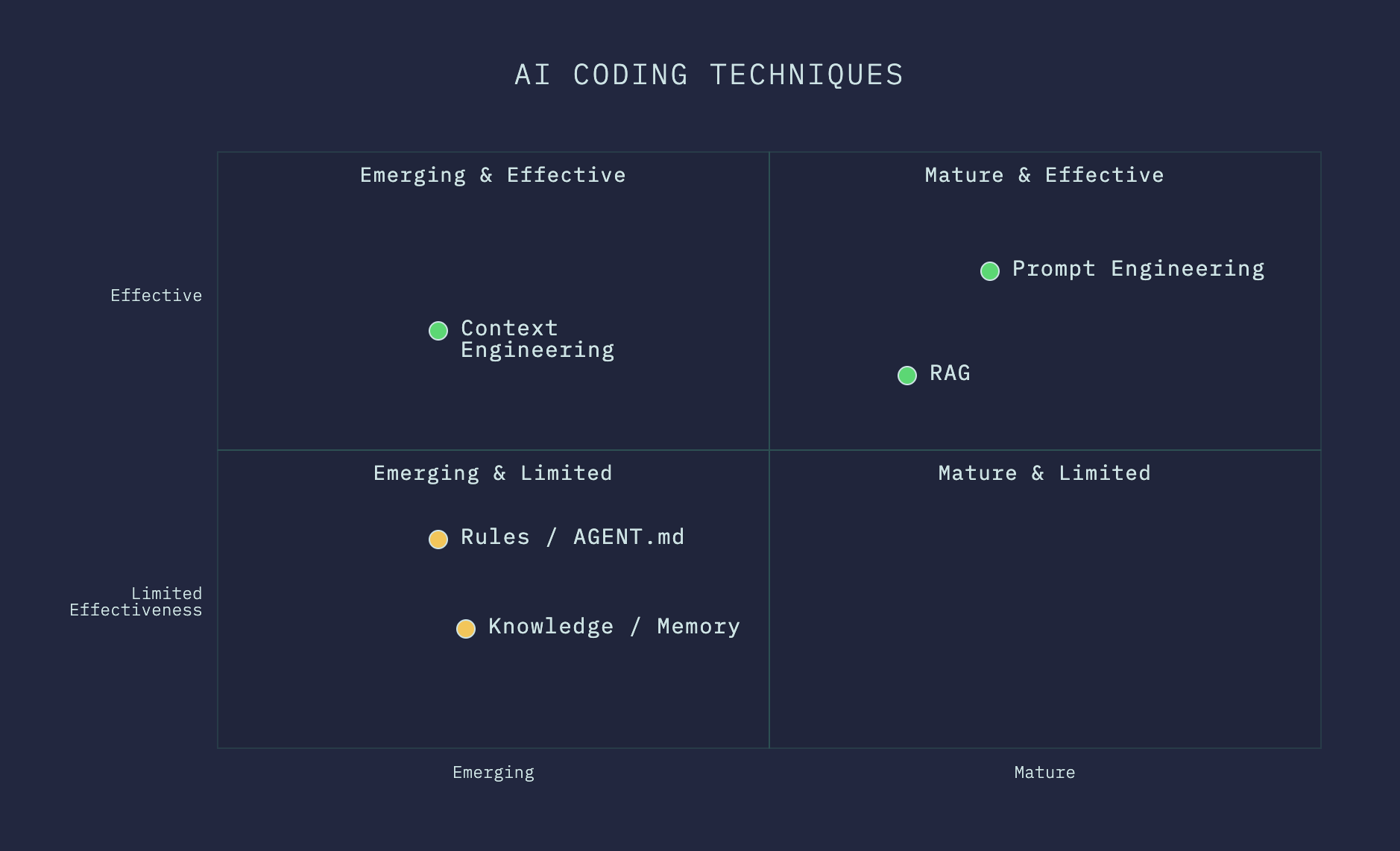
That's all for the techniques on input and context. Here’s summary of the techniques using a 2D quadrant visualization:
Check out part 2 of the series on tools and agents:
Effectiveness of AI Coding Techniques: Tools and Agents

In this post, we will analyze the effectiveness of AI coding techniques using tools and agents.
And subscribe to read new posts when they come out.
Check out my other works:
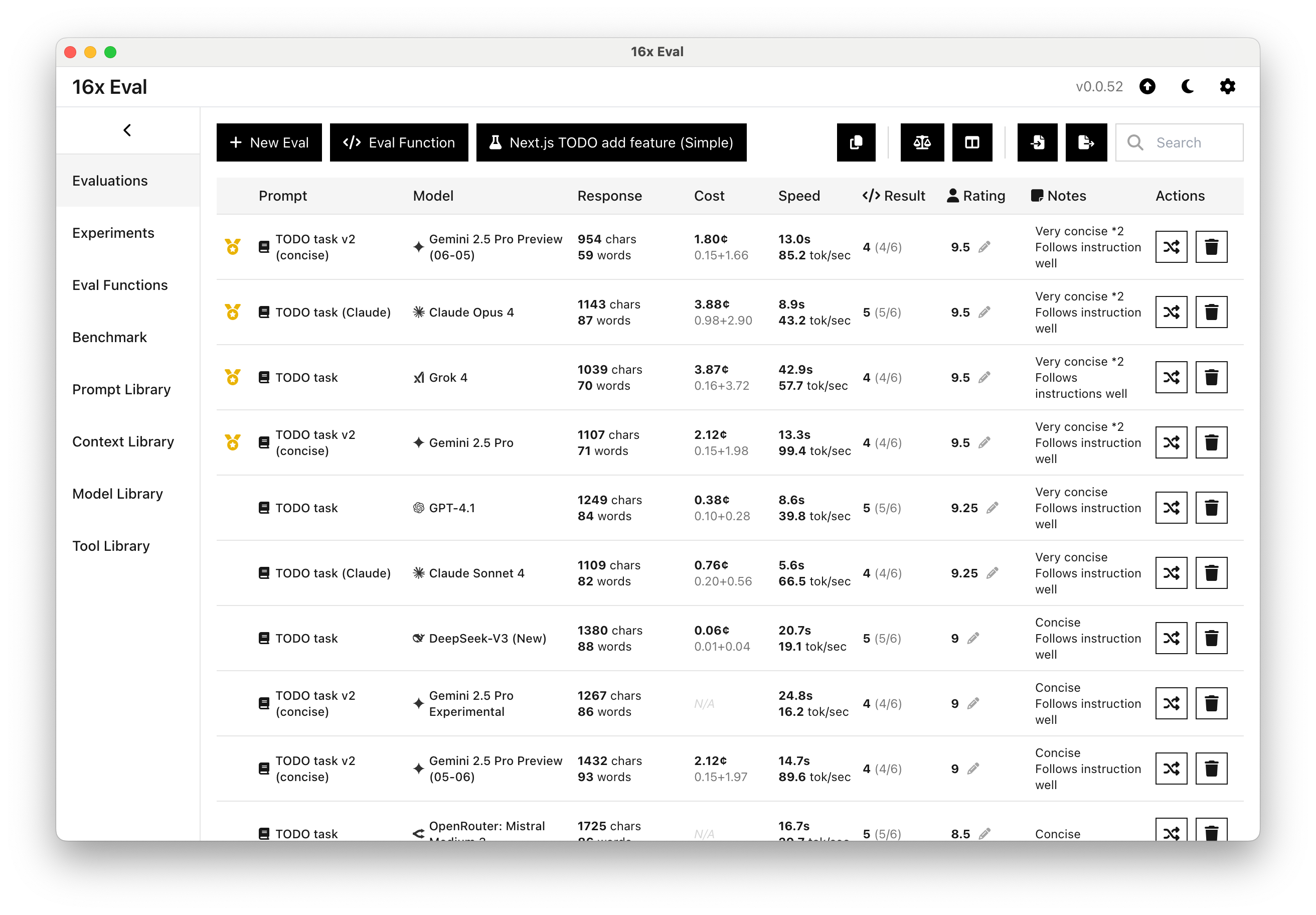
16x Eval - Simple desktop app for model evaluation and prompt engineering
16x AI coding stream - Weekly livestream where I build cool stuff using AI tools live on YouTube
Great breakdown and analysis!