
The Ground Truth Weekly - Effective Context Length and Block Diffusion
Weekly pick of interesting and noteworthy development in AI

Welcome to the first issue of The Ground Truth Weekly.
There are already a lot of AI news in the world, so I am going in a different direction.
No breaking news or top stories. I will be sharing the less known new developments or tools that are really interesting or noteworthy. I will also add my personal thoughts or experience with it where possible.
Effective Context Length - NOLIMA
Context window (context length) has become a widely known concept among AI adopters. It means how much text LLMs can see and process, before it starts forgetting the earliest part of the text.
With a 64k context window, you can fit 10 pages of pdf files (500 words *10 pages * 0.75 = 3750 tokens) into the LLM without any issue. But to fit Shakespeare’s complete works (884,647 words), you need 884647 * 0.75 = about 660k context window.
Newer models generally offer larger context window (Claude 3.5 Sonnet at 200K), and some models offer much larger context window (Gemini 2.0 Flash at 1M).
However, you should not dump everything into the context window just because the model supports it. A recent study has shown that LLMs suffer “performance degrades significantly as context length increases”.
In the paper titled NoLiMa: Long-Context Evaluation Beyond Literal Matching, the researchers found the following results:
We evaluate 12 popular LLMs that claim to support contexts of at least 128K tokens. While they perform well in short contexts (<1K), performance degrades significantly as context length increases. At 32K, for instance, 11 models drop below 50% of their strong short-length baselines.
Even GPT4o, one of the top-performing exceptions, experiences a reduction from an almost-perfect baseline of 99.3% to 69.7%.
Our analysis suggests these declines stem from the increased difficulty the attention mechanism faces in longer contexts when literal matches are absent, making it harder to retrieve relevant information.
Here’s a good graphical summary of results that I found from X:
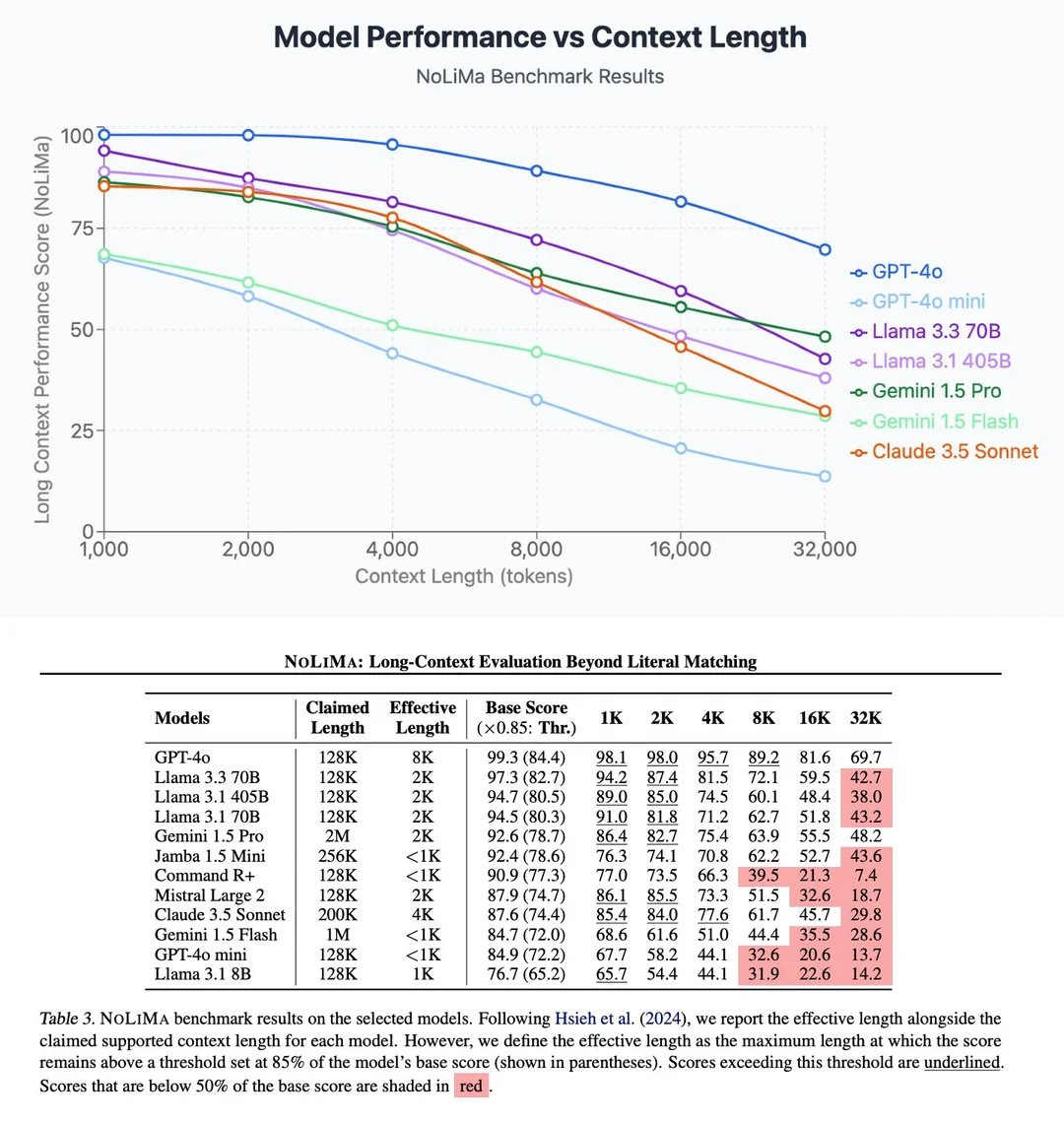
This research shows that for effective context retrieval, you want to keep the context at “effective context length” rather than the full context length. According to the paper:
We define the effective length as the maximum length at which the score remains above a threshold set at 85% of the model’s base score (shown in parentheses).
For GPT-4o, the effective length is 8K.
For Claude 3.5 Sonnet, the effective length is 4K.
For coding tasks, this research matches my personal experience. I found that adding unnecessary or irrelevant files degrades the output of LLMs for coding tasks.
I usually keep the context window very low (less than 8k) by only including the relevant source code when interacting with LLMs, whether through Cursor or my own AI coding tool 16x Prompt.
Key takeaway: Don’t stuff everything into the LLM context even if it is within the LLM’s context window, as it degrades the quality of output.
Update on 27 March 2025: There is new benchmark for effective context length: Fiction.liveBench, which is more granular and includes more models.
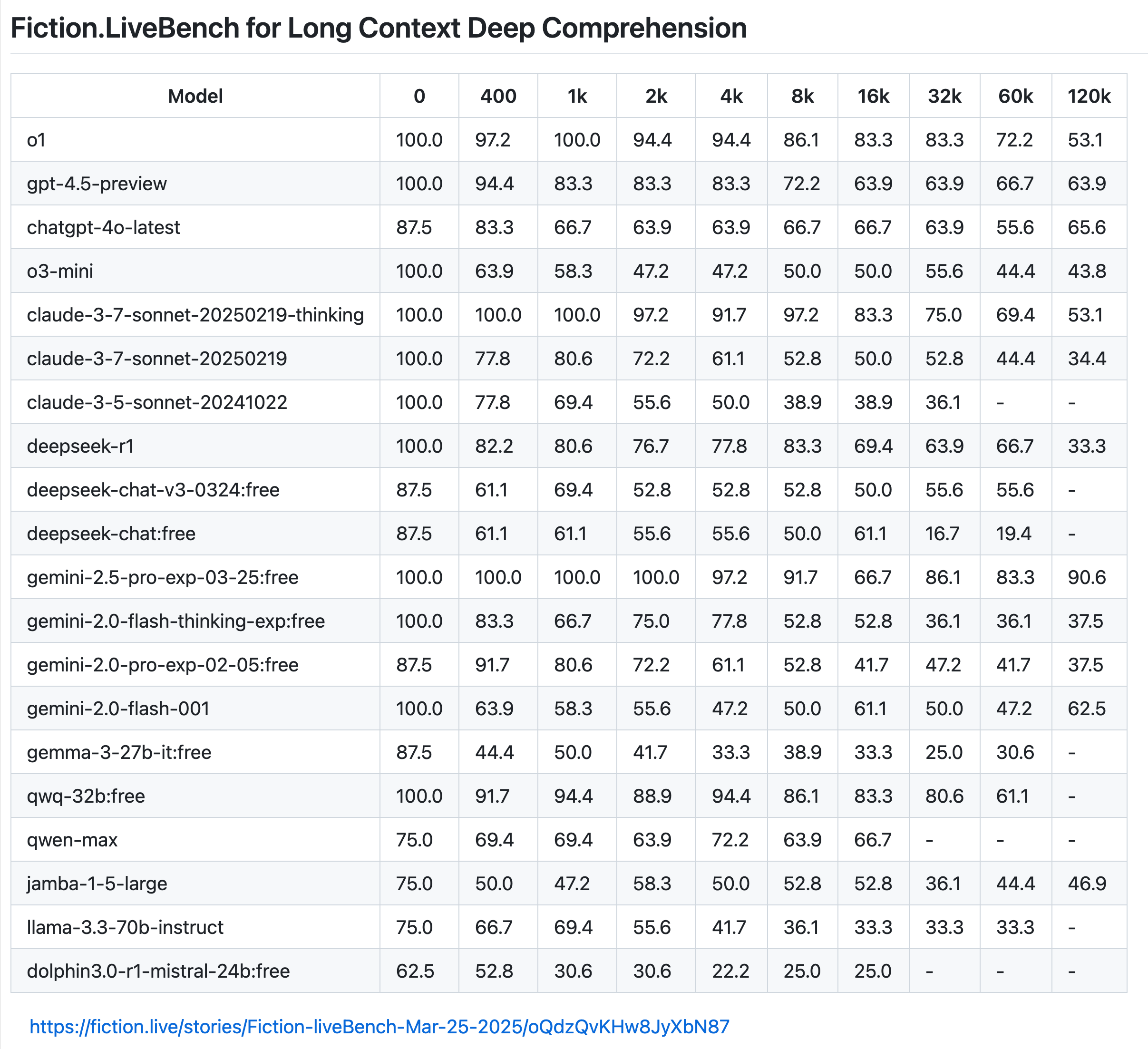
Based on the results, Google's Gemini 2.5 Pro is the best in handling long context, with no significant degradation even at 120k.
After that, o1 and Claude Sonnet 3.7-thinking are both quite good even at 32k.
Diffusion and Block Diffusion for LLMs
Traditionally, language models have been autoregressive models (generating one token at a time) in nature, whereas image generation models have been diffusion models (parallel).
In recent months, there were attempts to introduce diffusion as a technique for language models (SEDD, MDLM).
With each new technique, the performance of the diffusion-based model improves, but it is still behind autoregressive models (AR), when using perplexity as the metric of measurement:
Perplexity is essentially a measure of how many options the model finds plausible on average, with lower values indicating fewer options (more confident predictions) and higher values indicating more options (greater uncertainty).

Block diffusion (BD3-LM) is the latest attempt at this. Instead of generating the entire text with diffusion, block diffusion does it block by block:
Block diffusion language models (also known as semi-autoregressive models) interpolate between discrete denoising diffusion and autoregressive models.
Below is a recording of the animation on how it works:

With block size L′ at 4 (4 tokens per block), the performance of Block diffusion (BD3-LM) is closer to the autoregressive models on several datasets (Wikitext, LM1B, and AG News), compared to prior models (SEDD and MDLM).

Key takeaway: Diffusion models have not yet caught up with autoregressive models in terms of performance. However, they offer possibilities of much faster token generation as the generation can be parallelized instead of one token at a time.
Quick Mentions
A few other interesting things to watch out for:
VibeCode - An app that allows users to build mobile apps on mobile phones
Currently in waitlist with a few promotional videos on X.
Based on the promotional videos, the tech stack behind VibeCode is React Native and Expo, which I used a few years ago for building AI Simulator games.
I think this is a solid choice for vibe coding. React Native and Expo provide a lot of building blocks out-of-the-box for building mobile apps.
Also, the APIs and patterns for React Native / Expo are more well-defined compared to web technologies (React, Vue.js). End users should be able to build a useful mobile app really quickly.
Sakana AI - The AI Scientist Generates its First Peer-Reviewed Scientific Publication
A paper produced by The AI Scientist at Sakana AI passed the peer-review process at ICLR (a top machine learning conference) 2025 workshop track.
This is the first fully AI-generated paper that has passed the same peer-review process that human scientists go through.
ICLR 2025 features two tracks: a Conference Track and a Workshop Track.
Workshop track at a conference is typically less competitive compared to conference track.
That's it for the first issue of The Ground Truth Weekly. I hope you found it interesting.
Have something you want me to cover next time? Or thoughts on this issue? Feel free to reach out via LinkedIn. I'd love to hear how you're handling context window in your own work.
P.S. If you found this useful, share it with a friend who might enjoy reading.