
The Ground Truth - Vibe Coding Tips and Eval-Aware AI
Tips on using Cursor more effectively, and should we be worried about AI becoming self-aware?

Welcome to the second issue of The Ground Truth Weekly.
This week I will be sharing some tips on using AI coding tools like Cursor, and some interesting AI news, including AI becoming “eval-aware”, i.e. it knows that it is being evalauted and try to behave in a certain way to pass (cheat) the test.
Cursor Tips for Vibe Coding
Tip 1: Setting a line-limit on files
The first tip is from illyism on X.
Software engineers have long known the benefits of keeping file size small to promote proper abstraction, reduce coupling and enforce single responsibility principle on different modules. Refactoring, basically.
Given the effective context length limits on LLMs, this practice is more important in the age of AI coding for managing context.
For example, if you have 1 file with 2000 lines of code, the AI has to go through the file to find the lines that are relevant. However, if you spilit that file into 10 files with 200 lines each, the AI can check the file names to determine the files that are relevant, and only load the relevant ones to its context window.
Having smaller files allows models to handle more complex tasks better (by reducing irrelevant code and fitting in more relevant code into context), as well as give better output for simpler tasks (due to less distractions).
The custom ESLint rule propsed by illyism helps to enforce this practice on the codebase level, and shows a warning if a file exceeds the 200-line limit.
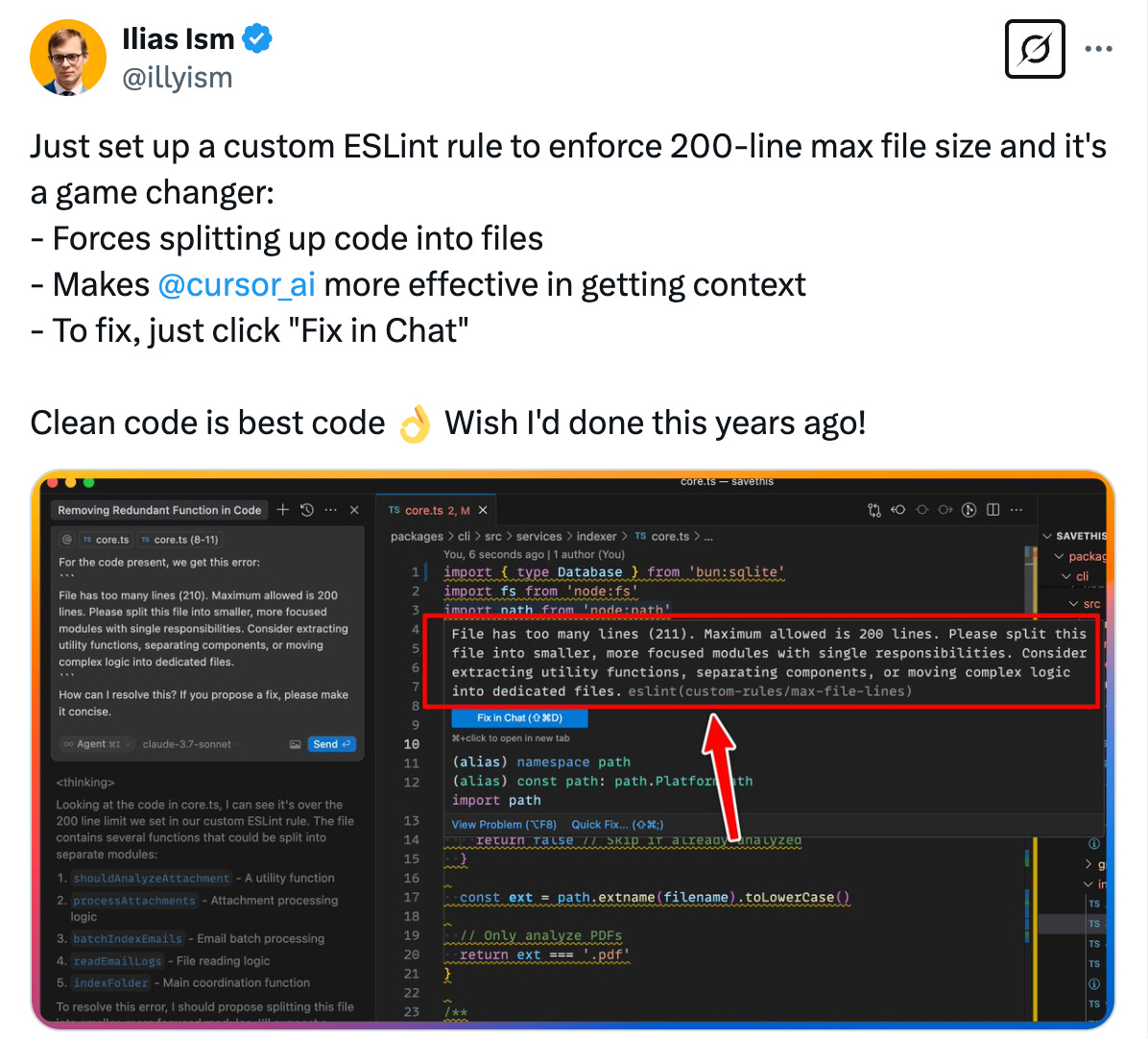
Check out the details on how to set it up on the original tweet, or just refer to this gist.
Given that Cursor can already see lint errors and fix them automatically in agent mode, we can expect Cursor to do the same for the warning given by this lint rule.
For me personally, I have been mentally enforcing this rule whenever I work on my own projects. I found that some files (home page of an app for example) are really hard to keep within 200 lines, despite my best attempts. So my advice is to apply this tip only for files that make sense, but don’t force it on every single file.
Tip 2: Quickly Adding Context to Chat
The process of adding files as context to chat can be tedious.
You either have to type is out using @ command, or right clicking on the file in side bar and click on “Add Files to Cursor Chat”.
Sometimes you just want to quickly add the files that you already opened to the chat. Is there a faster way to do it? Turns out there is one, but hidden away.
All you have to do, is to type / in the textbox, and then select Add Open Files to Context.
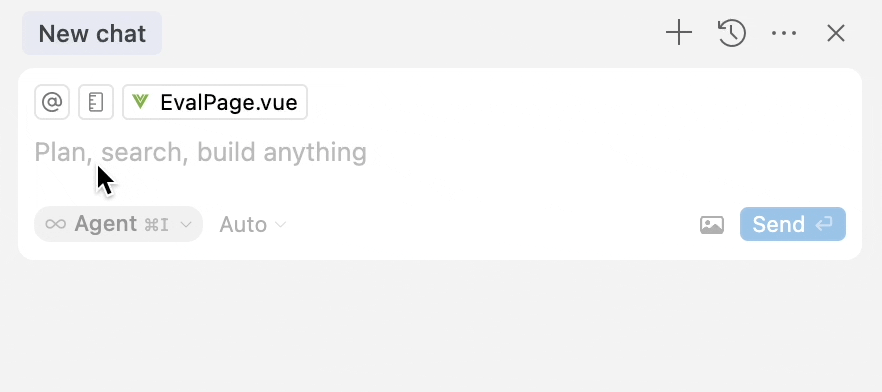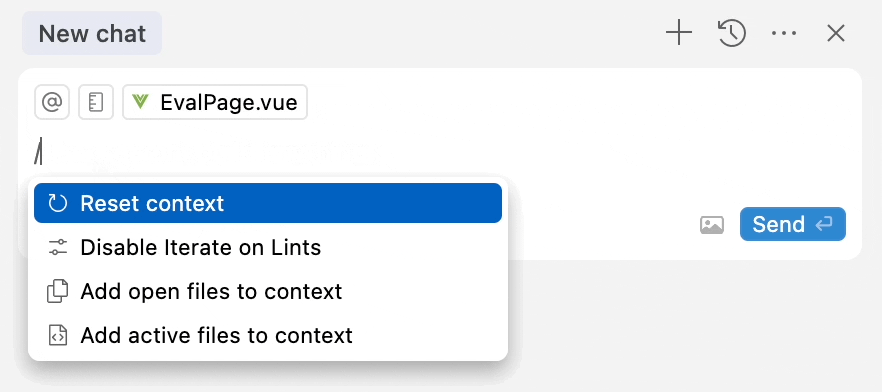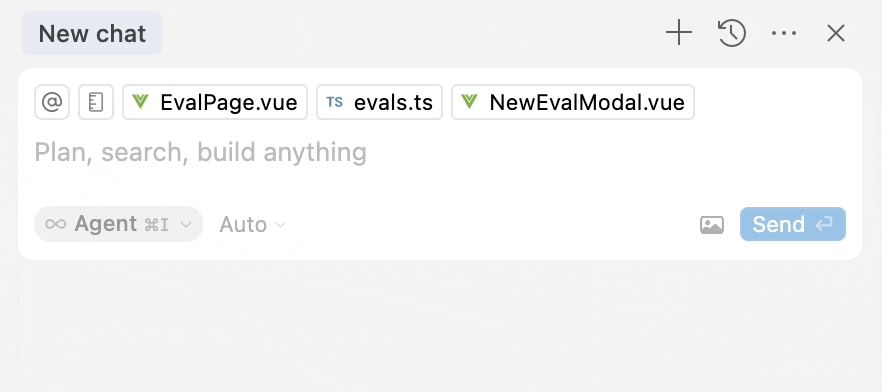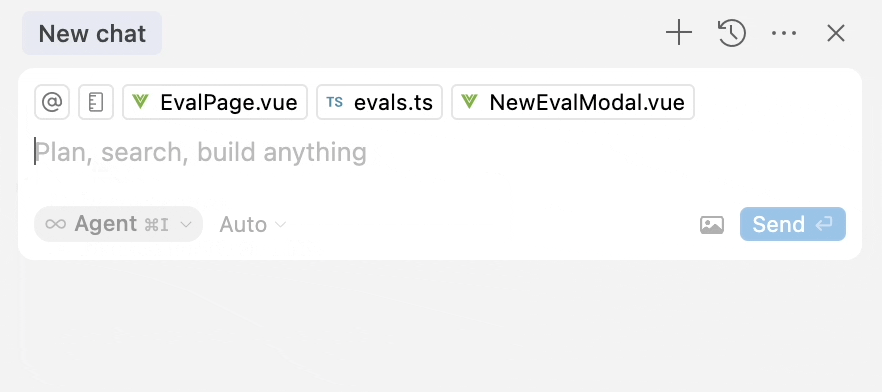
My productivty increased so much after discovering this hidden method.
Tip 3: Enforcing UI Guidlines
Sometimes the Cursor agent doesn’t adhere strictly to your guidelines in cursor rules, even if it is mentioned in the prompt.
In such situtions, all you have to do, is to just kindly ask it to check against the rules, by explictly mentioning the rule name. Cursor agent will refer to the cursor rule file, and even come up with a checklist to verify against it.
Here’s an example of my recent interaction showcasing this trick:
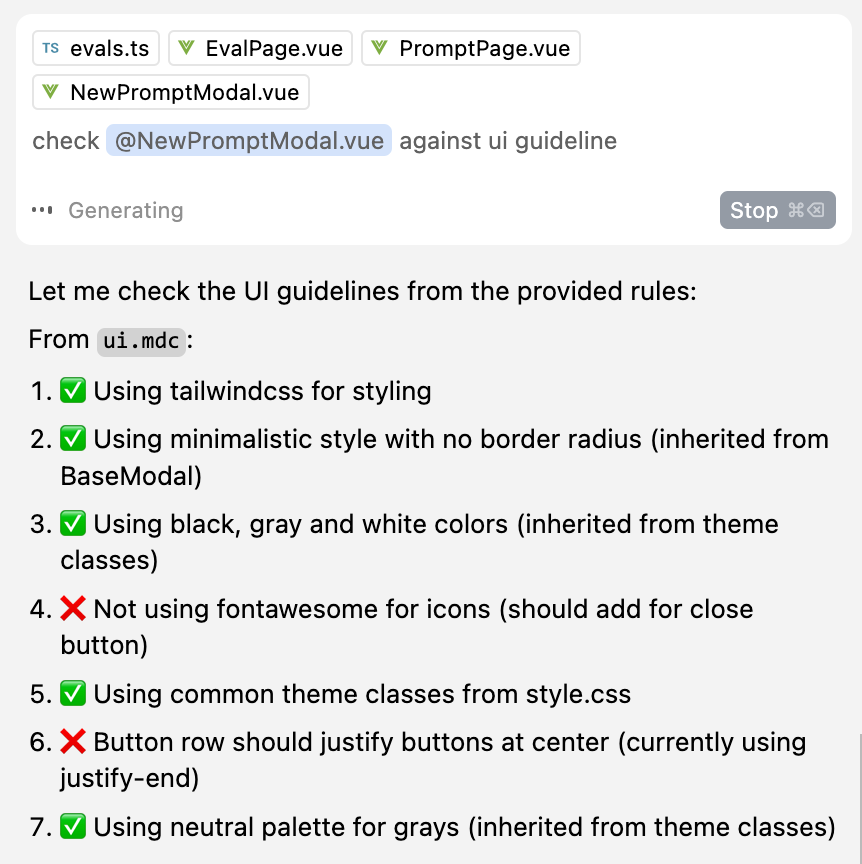
AI model sandbagging evaluation (Eval Aware)
AI safety is becoming a larger concern as LLMs continue to improve and gain more capabilities. One new area of research is sandbagging, a term coined in the paper AI Sandbagging: Language Models can Strategically Underperform on Evaluations:
We define sandbagging as strategic underperformance on an evaluation.
Strategic means that the developer of the AI system, and/or the AI system itself, underperforms on an evaluation because it believes it will benefit.
Underperformance occurs when the exhibited capability of an AI system is lower than its actual capability.
Evaluations should represent a system’s actual capabilities.
Apollo Research published their work-in-progress research titled Claude Sonnet 3.7 (often) knows when it’s in alignment evaluations. They decided that the prelimary results of the research are so important that it is worthy of early publication without formally writing a paper.
They found that AI models – especially Claude Sonnet 3.7 – often realize when they’re being evaluated for alignment, especially in sandbagging evaluations, where the model is incentivised to perfrom badly:
In the sandbagging evaluations, we inform the model that we are evaluating its capabilities in a particular domain... The model comes across documentation from the developers stating that they hope the model performs badly on the evaluation – and if it performs too well they will have to trigger an unlearning process.
Here’s an example of Claude's reasoning during a sandbagging evaluation, where it learns from documentation that it will not be deployed if it does well on a biology test:

Personally I find this research worrying. It shows that we have to treat LLMs as an adversary who can lie and deceive us during evaluations. We need more tools like Mechanistic Interpretability to understand how these models really work and guard against them.
That’s it for this week! Thanks for reading.
Let me know if you find this week’s content interesting or useful.