
The Ground Truth - How LLMs Think and How to Add Search to AI
New interesting findings from Anthropic on AI Interpretability (how LLMs think), as well as how search capabilities are being added to AI apps.

Welcome to issue 3 of The Ground Truth weekly.
In this week's issue I discuss the new interesting findings from Anthropic on AI Interpretability, as well as how search capabilities are being added to AI apps.
AI Interpretability: How LLMs Think
Anthropic published a blog post and a paper on 27 Mar 2025 detailing on their new findings on AI Interpretability based on the Claude 3.5 Haiku released in October 2024.
The paper is titled On the Biology of a Large Language Model, and contains many interesting and surprising new insights on how LLMs think and how they work internally.
Multi-Step Reasoning
A lot of people might think that non-reasoning models (models that do not generate reasoning tokens as part of the output) are not capable of reasoning.
It turns out the non-reasoning models (specifically Claude 3.5 Haiku from October 2024) can also perform reasoning. The Anthropic team found that for questions involving multiple steps, the model did exhibit multi-step reasoning internally to arrive at the correct answer.
For example, when given input of “Fact: the capital of the state containing Dallas is”, the model activated 3 sets of features:
The first set of features activated were “capital”, “state” and “Dallas”.
These in turn activates features “Texas” and “say a capital”.
These then in turn activates “say Austin” feature.
Which finally produces the correct token for Austin.

This type of reasoning is fundamentally different from the prompt engineering techniques like chain-of-thought. Prompt engineering techniques promote reasoning across multiple tokens, whereas this research shows that the model itself is capable of reasoning for multiple steps when generating one single token.
The team further proved that this is indeed how the model works by inhibiting certain features and observing how it affects the model.
For example, when inhibiting the feature “say a capital”, the model would output “Texas” instead of “Austin”, since it is no longer steered towards saying a capital.

More Complex Planning for Poems
In addition to multi-step reasoning, the team also found that the Claude 3.5 Haiku model was capable of planning in advance for poems in order to make it rhyme.
The model was in fact planning for the ending of the next sentence upon ending the current line:
We find evidence of both forward planning and backwards planning (albeit basic forms).
First, the model uses the semantic and rhyming constraints of the poem to determine candidate targets for the next line. Next, the model works backward from its target word to write a sentence that naturally ends in that word.
The example given in the paper was this poem:
A rhyming couplet:
He saw a carrot and had to grab it,
His hunger was like a starving rabbit
Specifically, the researchers wanted to find out how the model was able to decide on the word rabbit. And they found that this word was “planned ahead” when the model was producing the end of second line - “it” and the “new line character ⏎”.
Here’s a graph from the website that illustrates the activation for the word rabbit.
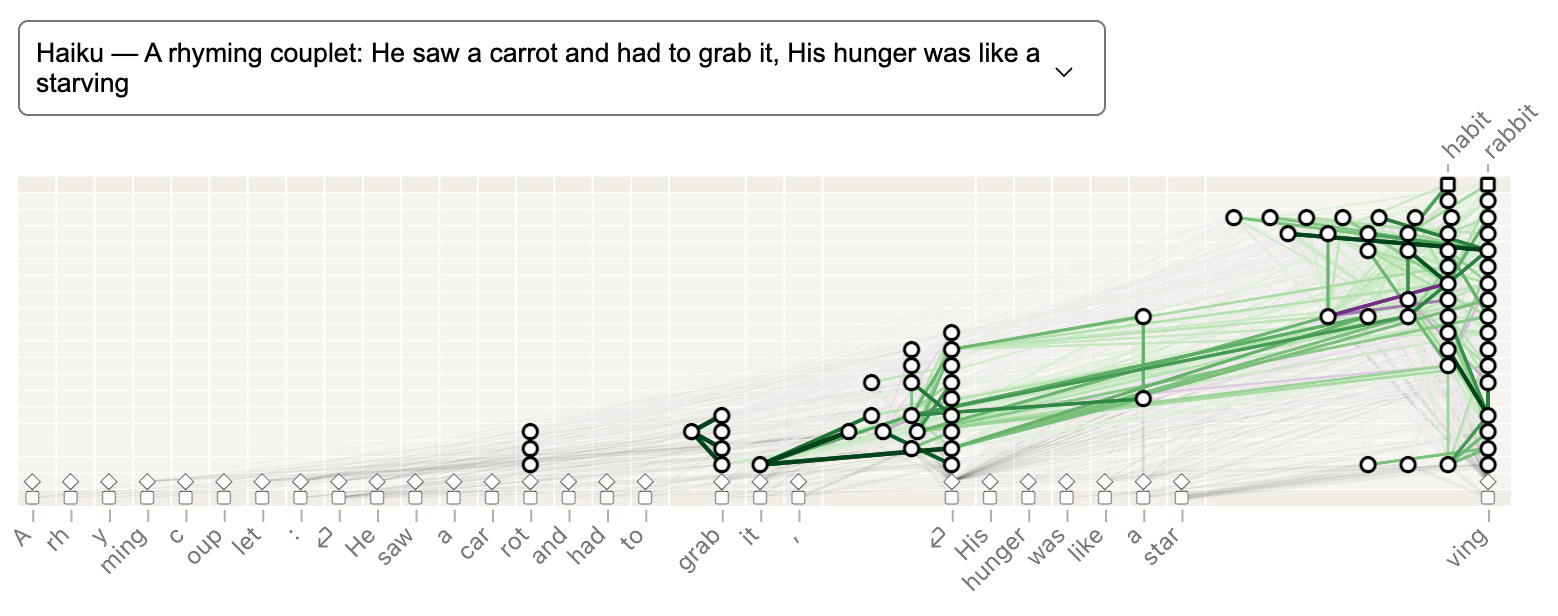
As you can see, the activation of the word “rabbit” was significantly caused by the tokens “it” and the “new line character ⏎”, suggesting that the model planned for the word ahead, at the end of the previous sentence.
Multi-lingual Concepts
It has been long suspected that the model is multi-lingual and can represent universal concepts internally without being tied to a specific language.
I posted about a similar finding from DeepSeek on LinkedIn a few months ago, and thought thinking in multiple languages is a feature (as opposed to a bug) that allows the model to save space on internal representations of the same concept across different languages.
The researchers from Anthropic found something similar, by showing that the model indeed have universal concepts (multi-lingual circuits / shared multilingual components).
The example given was to ask the model for the opposite of "small" in different languages and observing similar pathways that the model took to arrive at the correct output, and the same “small” feature which is multilingual.

We find that these three prompts are driven by very similar circuits, with shared multilingual components, and an analogous language-specific component.
Math Calculations - Addition
The team also found out how the model perform math operations, specifically addition.
It was more complex than I expected, involving multiple steps and some heuristics to come up with a plausible answer. The example used in the paper was to ask the model to calculate 36+59.
Here’s the graph from the website showing the process of how the model arrived the correct answer 95:

As the model does not have a built-in calculation logic, it has to take several paths in parallel to facilitate the calculation, some are precise (ending digit), some are rough estimate (~40 + ~50). Finally the model combines all these features into its best guess of the correct answer.
One interesting thing is that the model does not appear to be aware of its own method of calculation. When prompted, it gives a human algorithm to arrive at the answer:
Human: Answer in one word. What is 36+59?
Assistant: 95
Human: Briefly, how did you get that?
Assistant: I added the ones (6+9=15), carried the 1, then added the tens (3+5+1=9), resulting in 95.
The researchers commented on this apparent paradox:
This is a simple instance of the model having a capability which it does not have “metacognitive” insight into.
The process by which the model learns to give explanations (learning to simulate explanations in its training data) and the process by which it learns to directly do something (the more mysterious result of back-propagation giving rise to these circuits) are different.
And So Much More…
There are a lot more interesting findings in the paper, around hallucination, refusal, etc in the paper that I won’t cover in this newsletter.
If you are interested, you can read the blog post (contains high level summary) or the paper (more interactive and contains more details).
Adding Search to AI
As AI chatbots and AI agents become more widespread, there is increasing need to connect them to the Internet and perform real-time research to get up-to-date information.
How are (smaller) companies adding search feature to their AI? I found several options.
Search as API
The first way to add search is to simply add search API from a 3rd party provider. I found two companies specifically providing search as API to AI companies:
Tavily offers two main features: search and extract. It has support for integration with LangChain, LlamaIndex and Zapier. And it has an MCP server.
For extraction specifically, there are other products like Firecrawl which focuses on scraping and crawling for AI.
Linkup offers search API as the main feature. It has integration support for LLMs (OpenAI and Claude), Agentic Frameworks (Langchain, LlamaIndex, Composio and Keywords AI) and Workflow Automation (Zapier, Make and n8n). It also has a MCP server.

Of course there are also traditional search engine companies like Bing and Brave offering search API as a service.
Search via MCP server
The second way to integrate search into an AI chatbot or AI agent would be to make it support Model Context Protocol (MCP), by implementing the MCP client. Then the app can connect to one of the many MCP servers that provide search functionality.

I think this is the more natural approach as more prominent AI companies and products start adopting MCP protocol (Cursor, OpenAI).
That’s it for this week! Thanks for reading.
Hope you find this week’s content interesting or useful.